Мат, КАПС и XML-теги: мифы промптинга против данных
AI-модели в этой статье
«Напиши КАПСОМ – модель послушается». «Поругайся на неё – выдаст лучше». «Разбей на шаги – получишь глубокий анализ». Эти советы кочуют из блога в блог, из чата в чат. Кто-то ссылается на исследование Microsoft, кто-то – на личный опыт с ChatGPT.
Я решил проверить – и проверил основательно. Взял четыре модели, доступные в России без VPN: GigaChat-Ultra, GigaChat-2-Max, YandexGPT и Qwen3 Max. Каждую прогнал через десять техник промптинга (способов формулировать запросы к ИИ) – от простых ролевых заданий до XML-структур. Задачи – из реальной работы менеджера: анализ выручки, подготовка записки, увольнение по ТК РФ.
Оценивали вслепую два независимых LLM-судьи. Для калибровки те же задачи решали GPT-5.4 и Claude Sonnet – чтобы зафиксировать потолок, к которому тянутся российские модели.
Если вы используете ИИ для рабочих задач – записок, писем, анализа данных – эти результаты сэкономят часы проб и ошибок.
Половина популярных советов оказалась городскими легендами. Другая половина работает – но не так, как вы думаете.
Как мы это проверяли
Коротко, чтобы вы понимали, почему этим данным можно верить – и где их ограничения.
Каждую комбинацию «модель + техника + задача» прогнали несколько раз, чтобы результат не зависел от случайного везения. Оценка попарная: судья видит два ответа – наивный и улучшенный – и выбирает лучший. Судьи не знают, какая техника использована. Если не согласны – ничья.
Несколько важных оговорок. Оценку проводили LLM-судьи, а не люди. Все промпты написаны экспертом – типичный менеджер напишет проще, эффект будет меньше. Модели обновляются – результаты актуальны на апрель 2026.
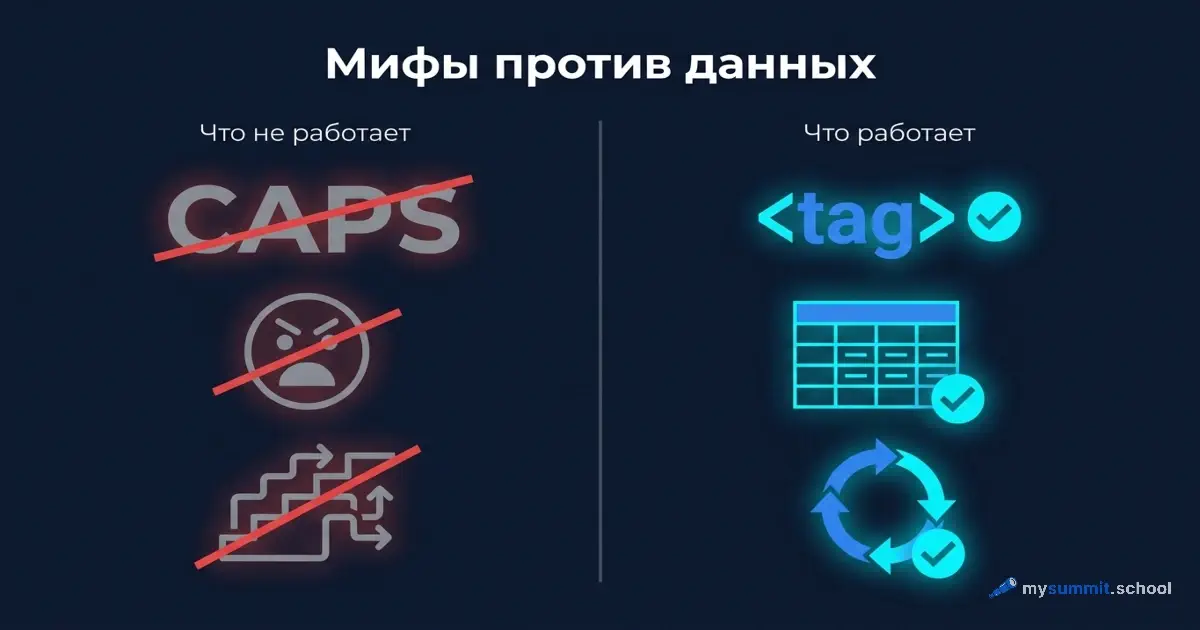
Миф 1: «Поругайся на неё – и она постарается»
Совет звучит логично – но работает ли он? Вы недовольны ответом, пишете резко – и модель «пугается», старается больше. На VC.ru Дмитрий Бескромный рассказывает, зачем матерится на ChatGPT. Tom’s Guide ввёл термин «rage prompt». Сергей Брин в январе 2026 заявил, что ругань на Claude улучшает результаты. А исследователи из Penn State (Dobariya & Kumar, 2025) замерили разницу: вежливые промпты дали 80,8% точности на ChatGPT-4o, грубые – 84,8%. Четыре процента – и заголовки полетели.
Удивительно, но на российских моделях данные говорят обратное – и это меня, честно говоря, удивило. YandexGPT отвечает хуже, когда на неё кричат.
Вероятный механизм: модель обучена на обратной связи от пользователей. Агрессивный тон она ассоциирует с ситуациями, где человек недоволен – и переключается в режим извинений. Вместо аналитики вы получаете «Вы правы, давайте попробуем ещё раз» с минимальными изменениями по сути.
Почему тогда люди уверены, что это работает? Потому что вместе с руганью они обычно добавляют конкретные инструкции. «Это ужасный ответ, ты не упомянул дедлайны, нет альтернативных вариантов, всё слишком абстрактно» – это не крик, это обратная связь. Помогает конкретика, а не тон. Если убрать эмоции и оставить инструкции – результат будет тот же или лучше. На «Сетке» пришли к тому же выводу: материться на нейросеть бесполезно – помогает структура запроса.
Миф 2: «Напиши КАПСОМ – модель обратит внимание»
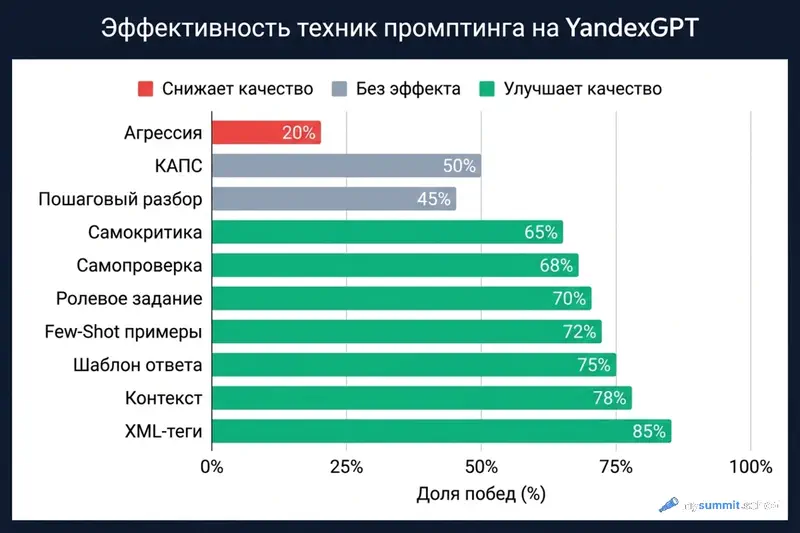
Ещё один популярный совет. В руководстве Microsoft по промпт-инжинирингу рекомендуют КАПС для заголовков секций – и этот совет быстро превратился в «пиши КАПСОМ, чтобы модель обратила внимание». Исследователь S. Anand протестировал чистый КАПС на десятке моделей: эффект составил 2–3%, при выборке в 10 запросов на модель – на уровне шума. Я повторил то же на российских моделях: те же самые слова, только БОЛЬШИМИ БУКВАМИ, без дополнительных указаний.
Разница с обычным текстом – на уровне статистического шума. КАПС не вредит, но и не помогает. Модель не «обращает внимание» на регистр так, как это делает человек. Для неё «ОБЯЗАТЕЛЬНО УКАЖИ ДЕДЛАЙНЫ» и «обязательно укажи дедлайны» – практически одно и то же.
Если вы привыкли писать КАПСОМ – это не мешает. Но если вы тратите время на расстановку акцентов через регистр, вы тратите его впустую. Лучше потратить его на секцию «ограничения и оговорки» в шаблоне ответа – это даст измеримый прирост.
Миф 3: «Разбей на шаги – получишь глубокий анализ»
Декомпозиция – техника, где вы разбиваете задачу на несколько последовательных вопросов. Сначала: «Проанализируй данные». Потом: «Теперь найди корневые причины». Потом: «Предложи план действий». Звучит разумно – вы ведёте модель за руку.
На YandexGPT это единственная техника, которая дала результат хуже наивного промпта.
Причина техническая: контекстное окно YandexGPT – 8 000 токенов. К третьему ходу диалога модель теряет данные из первого сообщения. Вы дали ей таблицу с выручкой в первом сообщении, попросили анализ во втором, а на третий ход она уже не помнит половину цифр. Ответ получается поверхностнее, чем если бы вы задали всё одним сообщением.
На моделях с большим контекстом – Qwen3 Max с его 128 000 токенов – декомпозиция работает. Но если ваш инструмент – Алиса в Яндекс Браузере или GigaChat в мобильном приложении, один хороший промпт лучше трёх простых вопросов.
Что реально работает
После трёх мифов – три техники, подтверждённые данными. Интересно, что все три решают одну и ту же слабость: YandexGPT хорошо пишет, но неглубоко думает. Модель не ленится – ей просто не сказали, что именно нужно проанализировать.
Шаблон ответа – одна минута, 75% побед
Самая простая техника с лучшим соотношением усилия и результата. Вы добавляете к своему вопросу шаблон – какие секции должны быть в ответе.
Вот пример. Допустим, клиент написал жалобу – третий раз за месяц заказ пришёл в повреждённой упаковке, угрожает уйти к конкурентам. Вместо «Как ответить клиенту и что делать?» вы пишете:
Клиент написал в поддержку: «Третий раз за месяц заказ приходит с повреждённой упаковкой. Прошлые два раза обещали разобраться, но ничего не изменилось. Если повторится – уйду к конкурентам». Клиент с нами 2 года, средний чек 12 000 руб./мес.
Ответь строго по формату:
- Краткий вывод (2–3 предложения)
- Ответ клиенту (готовый текст письма)
- Внутренние действия – что проверить, кого подключить, дедлайны
- Варианты компенсации с суммами
- Ограничения и оговорки
- Как предотвратить повторение
Ключевая секция – «Ограничения и оговорки». Без неё YandexGPT уверенно предложит план, не предупредив, что ей неизвестны детали логистики или условия договора. С ней – начинает помечать, где не уверена. Модель знает, что не знает. Но только если вы просите об этом явно.
XML-теги – структура, которая побеждает в 85% случаев
Когда данных много – цифры квартала, метрики команды, условия договора – свободный текст промпта превращается в кашу. XML-теги создают однозначные границы секций, которые модель разбирает точнее, чем сплошной текст.
<task>
Подготовить аналитическую записку для директора по итогам квартала.
</task>
<context>
Компания: интернет-магазин электроники, 45 сотрудников.
Рынок: бытовая электроника, средний сегмент.
</context>
<data>
- Выручка Q1: 42 млн руб. (план 51 млн, -18%)
- Трафик сайта: +12% к Q4 (рекламный бюджет +30%)
- Средний чек: снизился с 8 700 до 6 200 руб.
- Возвраты: выросли с 4% до 11%
- NPS: упал с 47 до 31
</data>
<output_format>
# Резюме для директора (3 предложения)
# Диагноз: что пошло не так
- Факт: цифра из данных
- Связь: как это повлияло на выручку
# План действий на Q2 (таблица: действие, эффект, срок)
# Чего мы не знаем (ограничения анализа)
</output_format>
<constraints>
- Каждый вывод привязывай к конкретной цифре из <data>
- Если данных недостаточно – укажи, какие нужны
- Без жаргона, с конкретными числами
</constraints>
Формат выглядит сложно – но собирается за десять минут, и его можно переиспользовать. Поменяйте содержимое <data> и <task>, оставьте структуру – и у вас готовый промпт для следующего квартала.
Исследования (научная статья) подтверждают: гибридные структуры дают непропорционально большой прирост именно на менее сильных моделях. GPT-5.4 справится и без тегов. YandexGPT – нет.
Шаблон и XML-теги решают одну задачу: превращают расплывчатый запрос в техническое задание для модели.
Шаблон и XML-теги – только два приёма из десяти. В открытом модуле – 9 задач менеджера, каждая со своей структурой промпта. Бесплатно, без регистрации.
Доступ сразу после регистрации
Самокритика – бонусный приём
Попросите модель перечитать собственный ответ. Этот промпт отправляется вторым сообщением – после того, как модель уже ответила:
Перечитай свой ответ. Найди 3 слабых места: где ты была неконкретна, где могли быть ошибки, что упустила. Затем дай улучшенную версию.
Академические работы показывают (научная статья), что малые модели не способны к полноценной самокритике – они не находят собственные ошибки, а «самоподтверждают» ответ. Я ожидал подтверждения – и получил нюанс.
Модель действительно не ловит фактические ошибки. Зато ловит пропуски: «не упомянула сроки», «не привела альтернативы», «не указала ограничения». Механизм скромнее, чем рефлексия, – модель просто сверяет ответ с представлением о полноте. Но для ежедневной работы этого достаточно.
Приём работает слабее, чем шаблон – нужен дополнительный запрос, а эффект скромнее. Но если ответ уже получен и вы хотите его улучшить без переписывания промпта с нуля – это рабочий вариант.

Одна проблема – три ответа
Чтобы разница была не абстрактной – вот как выглядит один и тот же вопрос при трёх подходах. Задача: выручка интернет-магазина упала на 18% при росте трафика на 12%.
Наивный промпт – «Выручка упала на 18%, трафик вырос на 12%. Что делать?» – даёт то, чего и ожидаешь: три абзаца общих рекомендаций без привязки к цифрам и без оговорок о том, что данных недостаточно.
Шаблон с форматом – уже другое. Модель связывает рост трафика с падением среднего чека – «реклама привлекает нецелевую аудиторию». Упоминает возвраты как отдельный сигнал. Даёт действия с дедлайнами. И – что важно – добавляет секцию «чего мы не знаем».
XML-шаблон идёт дальше. Модель выделяет три корневые причины, каждую привязывает к конкретной цифре. Замечает, что 40% заказов через новый склад при росте возвратов с 4% до 11% – вероятная связь. Предлагает проверить долю возвратов по складам. Формулирует план в виде таблицы. Явно перечисляет, каких данных не хватает.
Разница между первым и третьим ответом – не в качестве русского языка. YandexGPT и без тегов пишет грамотно. Разница в глубине анализа: модель перешла от «посоветовать что-нибудь общее» к «найти связи в данных и признать, где данных не хватает».
Вы только что видели, как один и тот же вопрос даёт три принципиально разных ответа. Но анализ выручки – лишь одна из десятков задач менеджера. Сложное письмо, план проекта, разбор конфликта – каждая требует своей структуры. Как её собрать – разбирается в открытом модуле курса, бесплатно.
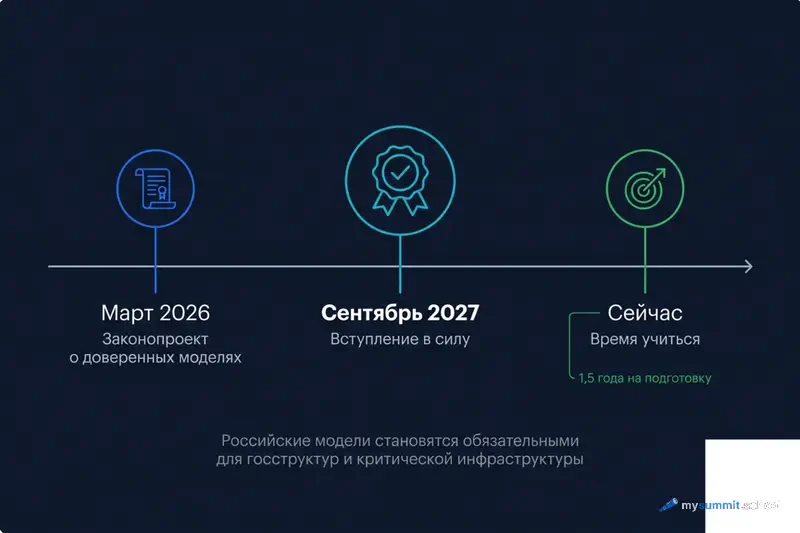
Почему это важно именно сейчас
В марте 2026 года Минцифры опубликовало законопроект о «доверенных моделях» ИИ. Если его примут – вступление в силу планируется с сентября 2027 – госструктуры и критическая инфраструктура смогут использовать только модели из реестра. ChatGPT, Claude и Gemini могут быть ограничены. На устройства планируется обязательная предустановка российских нейросетей.
В нашем исследовании GigaChat набрал 3,3 из 5, GPT-5.4 – 4,8. Разрыв – около 30%. Это значит, что навык работы с российскими моделями становится практической инвестицией: чем раньше вы научитесь получать от них максимум, тем меньше будет зависимость от доступа к зарубежным сервисам.
Промптинг этот разрыв полностью не закрывает. XML-шаблон поднимает YandexGPT, но не до уровня GPT-5.4 с наивным промптом. Однако он превращает модель из «советчика общих фраз» в аналитика, который работает с вашими данными. Для большинства ежедневных задач менеджера – подготовить записку, разобрать жалобу, спланировать разговор – этого достаточно.
Все три работающих техники решают одну задачу: они объясняют модели, чего именно вы хотите – вот структура, вот данные, вот что проверить. Модель та же. Качество ответа другое. Так в чём тогда была настоящая проблема?
Что забрать с собой
Структура важнее тона. КАПС, агрессия, «пожалуйста» и «спасибо» – всё это не влияет на качество ответа. Влияет другое: какие секции вы хотите видеть в ответе, какие данные предоставляете и какие ограничения задаёте.
Добавьте в шаблон одну секцию – «Ограничения и оговорки» – и модель перестаёт уверенно врать. Начинает отмечать, где данных не хватает, где выводы предварительные, что нужно проверить. На моделях с маленьким контекстом (YandexGPT, GigaChat) соберите всё в один запрос вместо цепочки вопросов – данные, задачу, формат, ограничения.
Парадокс в том, что техника с лучшим результатом – XML-шаблон, 85% побед – при этом та, которую используют реже всего: выглядит как код, пугает с первого взгляда. Шаблон ответа с 75% побед применяют чаще, потому что он похож на обычный запрос. Иногда барьер – внешний вид техники, а не её сложность.
Теперь вопрос: вы перестроите свой следующий промпт – или вернётесь к «напиши мне отчёт»?
Эта статья показала принцип. Но применить его к конкретным задачам – план проекта, сложное письмо, разбор конфликта, проверка договора – значит понимать, как промпт устроен и какой элемент за что отвечает.
Полные данные эксперимента – в интерактивном отчёте «Промпт-инжиниринг: что реально работает»: 10 техник, 4 модели, 1 717 запусков. Там же можно запустить любой промпт прямо в браузере.
От приёма к системе: девять задач менеджера
Структура промпта решает разово. Систематический результат на любой задаче – от плана проекта до разбора конфликта – даёт фундамент курса. Открытый модуль: 9 задач менеджера, каждая со своей структурой. Бесплатно.


Stanislav Belyaev
Engineering Leader в Microsoft18 лет в управлении инженерными командами. Основатель mysummit.school. 700+ выпускников в Яндекс Практикуме и Стратоплане.